Friday the 3th of November I presented my work at the University of Twente to my fellow students and my supervisors. The slides of this presentation are available through this link:
Presentation at University of Twente, 3th of November 2006
All students and supervisors present that day are encouraged to post their comments.
Monday, November 06, 2006
Tuesday, October 31, 2006
New test strategy for SQLbusRT
The test results that I have generated before (see my previous post) did not really help me in reaching my project goal, which is to make it possible to predict SQLbusRT's performance, reliability and scalability when it is used in an application.
In my new strategy I'm gonna take one step at a time to put the different components of SQLbusRT to the test.
My first upcoming test will involve sending messages back and forth between two processes, using the ORTE communication bus. This way, I can really measure ORTE's performance and reliability alone, without influence of MySQL. I will perform this test in different scenario's which will let me determine the scalability as well.
After having processed the results of these tests, I will include MySQL. Making these separate tests will let me determine the influence of ORTE and MySQL separately.
The new test results will of course be posted here again as soon as they are processed.
In my new strategy I'm gonna take one step at a time to put the different components of SQLbusRT to the test.
My first upcoming test will involve sending messages back and forth between two processes, using the ORTE communication bus. This way, I can really measure ORTE's performance and reliability alone, without influence of MySQL. I will perform this test in different scenario's which will let me determine the scalability as well.
After having processed the results of these tests, I will include MySQL. Making these separate tests will let me determine the influence of ORTE and MySQL separately.
The new test results will of course be posted here again as soon as they are processed.
Wednesday, October 04, 2006
Presenting the first SQLbusRT test results
Here it is, a presentation after my first tests. Open the slides by clicking here. (Or right click, save as...).
The presentation is not exhaustive if it comes to the test results, so if anyone is interested in the log files themselves, you can drop me an email at bram.smulders-at-imtech.nl or post a comment with your email address.
The presentation is not exhaustive if it comes to the test results, so if anyone is interested in the log files themselves, you can drop me an email at bram.smulders-at-imtech.nl or post a comment with your email address.
Wednesday, September 20, 2006
SQLbusRT: First test version is running!
Today I have some good news to announce! Finally, after quite some struggles and some disappointments because of 'optimistic planning', I can tell you that the first version is working.
It is a testing version which has the following functionality:
- An example sensor publishes random values on the bus;
- A insertion interface reads all sensor data on the bus (it is ready to receive data from multiple sensors) and writes it to the database. It creates tables for every new sensor;
- A selection interface listens to SQL requests and creates data sources which publish data on the bus at a specified interval;
- An example client publishes it's request on the bus and after receiving a data source ID, subscribes to this data source. It will from thereon receive the result periodically.
I will add some logging to the code now so I can extract some meaningful performance information.
I will present the performance measures to my colleagues next Monday. Afterwards, I will put the slides online.
It is a testing version which has the following functionality:
- An example sensor publishes random values on the bus;
- A insertion interface reads all sensor data on the bus (it is ready to receive data from multiple sensors) and writes it to the database. It creates tables for every new sensor;
- A selection interface listens to SQL requests and creates data sources which publish data on the bus at a specified interval;
- An example client publishes it's request on the bus and after receiving a data source ID, subscribes to this data source. It will from thereon receive the result periodically.
I will add some logging to the code now so I can extract some meaningful performance information.
I will present the performance measures to my colleagues next Monday. Afterwards, I will put the slides online.
Monday, September 18, 2006
Back to work (and more on ORTE)
After coming back from holidays on the 6th of September, I've been able to work on the project with a refreshed mind again!
I expected to have finished coding by now, but after putting all the components together, I ran into an occasional 'segmentation fault'. I've been looking for the problem, but only with the help from one of my colleagues I was able to address the causes.
For the first cause, I should explain a little bit about how ORTE handles issues:
As I explained before, ORTE works with 'publishers' and 'subscribers'. ORTE periodically invokes a callback function on the publisher side, which is meant to prepare the data for sending in a memory buffer. When the callback function finishes, ORTE reads the buffer and copies it to a memory buffer on the subscriber side. It then invokes the subscriber callback function which is meant to process the incoming data.
So what went wrong in my implementation?
My request handler acts as a subscriber for requests. Whenever a request comes in, it behaves as a publisher to notify the requesting client on the data source ID. (You can find this scenario in the diagram added to my post of the 3th of August.)
I used the request handler's subscriber callback function to immediately create a publication of the data source ID. And that was the problem! ORTE only allows creation of publications in the main thread. When you try to create it in the subscriber callback function, it will be handled in another thread, causing it to fail.
I have already fixed this problem by placing the creation of the publication in the main thread, controlling it with the use of semaphores.
What about the second cause?
The second cause for the segmentation faults was caused by my enthusiasm to free memory as soon as possible.
After making the request handler send the data source ID, I immediately freed the memory used by this publication. The C code looks like this:
//p is the publication handle
ORTEPublicationSend(p); //sending the issue
ORTEPublicationDestroy(p); //destroy the publication handle
I expected the ORTEPublicationSend function to be locking the thread until the entire publication had been finished, but it turns out to be a false assumption. With the code above, I was destroying the publication handle before the publication was finished completely, causing a segmentation fault.
This issue has been fixed with a workaround for now.
What coding is still to be done?
For my first measurements, I have to set up all the data sources in different threads. Using the metaphors fixing one issue has introduced a new one. It prevents the data sources from sending data.
After this, I will give my code a review, and I will invite a colleague to review my code critically.
I expected to have finished coding by now, but after putting all the components together, I ran into an occasional 'segmentation fault'. I've been looking for the problem, but only with the help from one of my colleagues I was able to address the causes.
For the first cause, I should explain a little bit about how ORTE handles issues:
As I explained before, ORTE works with 'publishers' and 'subscribers'. ORTE periodically invokes a callback function on the publisher side, which is meant to prepare the data for sending in a memory buffer. When the callback function finishes, ORTE reads the buffer and copies it to a memory buffer on the subscriber side. It then invokes the subscriber callback function which is meant to process the incoming data.
So what went wrong in my implementation?
My request handler acts as a subscriber for requests. Whenever a request comes in, it behaves as a publisher to notify the requesting client on the data source ID. (You can find this scenario in the diagram added to my post of the 3th of August.)
I used the request handler's subscriber callback function to immediately create a publication of the data source ID. And that was the problem! ORTE only allows creation of publications in the main thread. When you try to create it in the subscriber callback function, it will be handled in another thread, causing it to fail.
I have already fixed this problem by placing the creation of the publication in the main thread, controlling it with the use of semaphores.
What about the second cause?
The second cause for the segmentation faults was caused by my enthusiasm to free memory as soon as possible.
After making the request handler send the data source ID, I immediately freed the memory used by this publication. The C code looks like this:
//p is the publication handle
ORTEPublicationSend(p); //sending the issue
ORTEPublicationDestroy(p); //destroy the publication handle
I expected the ORTEPublicationSend function to be locking the thread until the entire publication had been finished, but it turns out to be a false assumption. With the code above, I was destroying the publication handle before the publication was finished completely, causing a segmentation fault.
This issue has been fixed with a workaround for now.
What coding is still to be done?
For my first measurements, I have to set up all the data sources in different threads. Using the metaphors fixing one issue has introduced a new one. It prevents the data sources from sending data.
After this, I will give my code a review, and I will invite a colleague to review my code critically.
Spam has arrived!
Unfortunately, after having my blog on the net for about 4 months, spam bots have found my blog. To prevent any further bot comments to appear on my blog, I've switched on 'word verification' for comments.
Please don't let it hold you back from posting comments on my blog. All your (non-spam) input is very much appreciated!
Please don't let it hold you back from posting comments on my blog. All your (non-spam) input is very much appreciated!
Thursday, August 24, 2006
Status update on SQLbusRT
I'll be on holidays from the 25th of August till the 5th of September. Therefore, I thought it would be a good idea to give an update on the current status of SQLbusRT.
Coding has almost finished. With almost finished, I mean it is almost ready for the first test runs. It is still a very simple implementation. It will give me some baseline figures when I execute my first performance tests, but it does not have all the planned functionality yet.
I'm not publishing the code yet. I want to have the code reviewed by some collegues first, and perhaps it's better to wait for the results of the first test runs to see whether the taken approach is a good one.
I've finished setting up a network of computers to run my tests on. All computers run linux, with the possibility of choosing a patched or an unpatched kernel on boot. The patched kernel offers preemption. This will be used to give real time priority to the incoming data from the network adapters. I'll give more detailed information on this after my holidays.
The 6th of September I'll be running those first test runs. As soon as some useful data has been extracted, it'll be posted here.
Coding has almost finished. With almost finished, I mean it is almost ready for the first test runs. It is still a very simple implementation. It will give me some baseline figures when I execute my first performance tests, but it does not have all the planned functionality yet.
I'm not publishing the code yet. I want to have the code reviewed by some collegues first, and perhaps it's better to wait for the results of the first test runs to see whether the taken approach is a good one.
I've finished setting up a network of computers to run my tests on. All computers run linux, with the possibility of choosing a patched or an unpatched kernel on boot. The patched kernel offers preemption. This will be used to give real time priority to the incoming data from the network adapters. I'll give more detailed information on this after my holidays.
The 6th of September I'll be running those first test runs. As soon as some useful data has been extracted, it'll be posted here.
Thursday, August 03, 2006
Handling SQL requests in SQLbusRT
While implementing the first test version of SQLbusRT, I faced a problem on how to communicate SQL requests and query results using ORTE as a medium.
Usually when doing an SQL request, a connection is set up between a client and an SQL server. The client sends its SQL request over this connection, and as an answer it receives the query results over the same channel. Unfortunately, in the bus architecture I have in mind things aren't that simple...
Remind the fact that SQLbusRT is built on top of a publish/subscribe model. Ideally speaking clients should be subscribers, and the database server should be a publisher. However, this introduces a problem for both instances:
This idea however was not complete. While struggling with the question on how to actually implement this using publish/subscribe, I came up with the following:
It also shows at what time subscriptions are being created in handlers and clients.
 (Click to enlarge)
(Click to enlarge)
Note: The SQLrequest as you see it in the diagram is an object, containing the clientID, requestID and the actual SQL query. The response is also an object, containing the publicationID and requestID.
Working this way has a great benefit when multiple clients are making the same periodic or triggered request. The data only has to be fetched from the database once and will be distributed automatically, by letting the requesting clients subscribe to the same publication.
Usually when doing an SQL request, a connection is set up between a client and an SQL server. The client sends its SQL request over this connection, and as an answer it receives the query results over the same channel. Unfortunately, in the bus architecture I have in mind things aren't that simple...
Remind the fact that SQLbusRT is built on top of a publish/subscribe model. Ideally speaking clients should be subscribers, and the database server should be a publisher. However, this introduces a problem for both instances:
- How does the publisher know what to publish?
- What should the subscriber subscribe to?
This idea however was not complete. While struggling with the question on how to actually implement this using publish/subscribe, I came up with the following:
- The request handler has a subscriptions for SQL requests
- The client publishes an SQL request
- The client creates a subscription for information from the request handler
- The request handler sends information on which data source to subscribe to
- The request handler sets up a publication for the new request
- The client subscribes to the correct data source
It also shows at what time subscriptions are being created in handlers and clients.
 (Click to enlarge)
(Click to enlarge)Note: The SQLrequest as you see it in the diagram is an object, containing the clientID, requestID and the actual SQL query. The response is also an object, containing the publicationID and requestID.
Working this way has a great benefit when multiple clients are making the same periodic or triggered request. The data only has to be fetched from the database once and will be distributed automatically, by letting the requesting clients subscribe to the same publication.
Friday, July 28, 2006
Development update
Since it is two weeks ago since my last post, I thought it would be a good idea to give a quick update on the development status.
At present, I've tackled all include and linking problems I faced (C++ is rather new to me). The insertion interface is ready, and the API for clients and sensors is near completion.
Last things remaining are the selection interface, an example client and an example sensor.
In a couple of days I hope to publish a package containing the first version.
At present, I've tackled all include and linking problems I faced (C++ is rather new to me). The insertion interface is ready, and the API for clients and sensors is near completion.
Last things remaining are the selection interface, an example client and an example sensor.
In a couple of days I hope to publish a package containing the first version.
Friday, July 14, 2006
Development picked up again
Some weeks back I posted that the development of SQLbusRT had started. After some days this task had been postponed to reconsider the architectural design and to do some more theoretical research.
The version I started was programmed in C, which seemed to be a logical choice since there's a good ORTE API in C.
Yesterday I restarted the coding, now with C++ as the language. It's still possible to use the C API for ORTE, but it also allows me to have an object oriented approach.
The following components will be present in the first release:
The version I started was programmed in C, which seemed to be a logical choice since there's a good ORTE API in C.
Yesterday I restarted the coding, now with C++ as the language. It's still possible to use the C API for ORTE, but it also allows me to have an object oriented approach.
The following components will be present in the first release:
- A tiny API for writing simple clients and sensors
- An insertion interface, which writes the sensor data to the database
- A selection interface, which handles query requests from clients
- A small example client and sensor
Friday, July 07, 2006
Performance, Reliability and Scalability
It is always nice to be able to say a system "performs well", is very "reliable" or is "scalable". But what do these terms actually mean?
One of the primary goals of my research on SQLbusRT is finding formulas which can predict the performance, reliability and scalability of the system under development, looking at the scenario it is implemented in.
Ofcourse saying "good performance", "very reliable" and "yes it is scalable" does not suffice. The formulas should provide a meaningful outcome, which is comparable to other outcomes.
I might not be clear to everyone. Let me give an example, using something we always like to talk about: the weather.
We can say the weather is good or bad today, but that is just a personal opinion. If we want to compare todays weather with the weather of tomorrow for instance, we need numbers. We can give useful information on the weather by giving:
The more I read about it on the net, the more questions come in mind. I already found some scientific articles on the web which might help me, but I'm still looking for some more information. Especially scalability is often rather vague.
If someone knows any clear information on this matter, you're heartily invited to post a comment on this issue. You can help me a lot by doing so. All help is very much appreciated.
PS. I know that performance, reliability and scalability might have different meanings in different situations. Therefore, it is good to know that the system under development is a publish subscribe model with history added. You can find images explaining the architecture in my previous posts. Once again, all help is very much appreciated.
One of the primary goals of my research on SQLbusRT is finding formulas which can predict the performance, reliability and scalability of the system under development, looking at the scenario it is implemented in.
Ofcourse saying "good performance", "very reliable" and "yes it is scalable" does not suffice. The formulas should provide a meaningful outcome, which is comparable to other outcomes.
I might not be clear to everyone. Let me give an example, using something we always like to talk about: the weather.
We can say the weather is good or bad today, but that is just a personal opinion. If we want to compare todays weather with the weather of tomorrow for instance, we need numbers. We can give useful information on the weather by giving:
- The temperature in Degrees Celcius or Fahrenheit (min, max, current)
- The humidity in %
- The wind speed in km/hour or miles/hour
- ...
The more I read about it on the net, the more questions come in mind. I already found some scientific articles on the web which might help me, but I'm still looking for some more information. Especially scalability is often rather vague.
If someone knows any clear information on this matter, you're heartily invited to post a comment on this issue. You can help me a lot by doing so. All help is very much appreciated.
PS. I know that performance, reliability and scalability might have different meanings in different situations. Therefore, it is good to know that the system under development is a publish subscribe model with history added. You can find images explaining the architecture in my previous posts. Once again, all help is very much appreciated.
Thursday, June 29, 2006
Clarified architecture
Some weeks back I posted two diagrams with the architecture for SQLbusRT. One was for one database instance, and one was for multiple databases.
After reading a bit on about the triggers and events in MySQL 5.x, I decided to revise the architecture slightly. In my previous architecture, I had taken event handling outside of the database, but since MySQL supports triggers and events, there is no need to do this anymore.
I've not only taken out the event handling, I've also enhanced the readability of the diagram. To sum it up, these changes have been made:
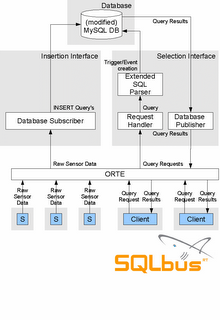 One thing about the processes is important to understand: ORTE didn't get it's own grey process box, because the amount of processes running for ORTE depends on the number of systems connected to the ORTE bus.
One thing about the processes is important to understand: ORTE didn't get it's own grey process box, because the amount of processes running for ORTE depends on the number of systems connected to the ORTE bus.
For every network interface connected to the ORTE bus, one "ORTE manager" is started. This manager handles the connections between the publishers and the subscribers. E.g., when all processes are running on one machine, then one ORTE manager will be running. Distributing the processes over multiple machines will increase the number of ORTE managers.
After reading a bit on about the triggers and events in MySQL 5.x, I decided to revise the architecture slightly. In my previous architecture, I had taken event handling outside of the database, but since MySQL supports triggers and events, there is no need to do this anymore.
I've not only taken out the event handling, I've also enhanced the readability of the diagram. To sum it up, these changes have been made:
- Event handling is now handled inside the database, and has therefore been taken out of the diagram
- The edges are now labeled for clarification
- Grey boxes have been added to show the process boundaries; every box is one single process
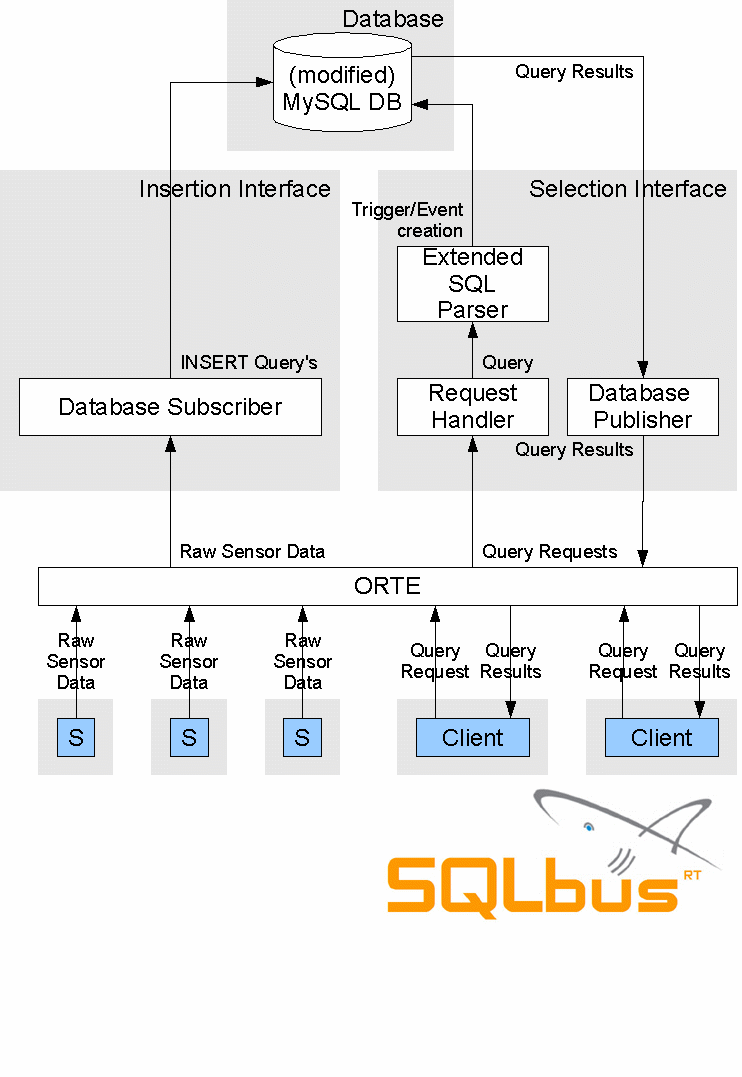 One thing about the processes is important to understand: ORTE didn't get it's own grey process box, because the amount of processes running for ORTE depends on the number of systems connected to the ORTE bus.
One thing about the processes is important to understand: ORTE didn't get it's own grey process box, because the amount of processes running for ORTE depends on the number of systems connected to the ORTE bus.For every network interface connected to the ORTE bus, one "ORTE manager" is started. This manager handles the connections between the publishers and the subscribers. E.g., when all processes are running on one machine, then one ORTE manager will be running. Distributing the processes over multiple machines will increase the number of ORTE managers.
Wednesday, June 28, 2006
Planet MySQL
This blog has been added to the MySQL developer zone!
You can reach it by going to the MySQL website and clicking Developer Zone -> blogs. This brings you to the Planet MySQL, which now contains this blog.
You can also go there directly by following this link: Planet MySQL
You can reach it by going to the MySQL website and clicking Developer Zone -> blogs. This brings you to the Planet MySQL, which now contains this blog.
You can also go there directly by following this link: Planet MySQL
Wednesday, June 21, 2006
New presentation
Last Friday, my mentor from the university came to visit Imtech ICT. To explain him what the project is all about, I gave a short presentation. The presentation contains some of the elements that are also present in the presentation that I posted on the 29th of May, but this new presentation focusses on the project instead of the product.
I'm sorry English readers, this presentation is in Dutch.
The presentation can be downloaded here: Kennismaking
I'm sorry English readers, this presentation is in Dutch.
The presentation can be downloaded here: Kennismaking
Thursday, June 08, 2006
Development has started
The development of a prototype of SQLbusRT has started.
This first version will contain an implementation of all the components in the current architectural design. However, these components will not contain much functionality yet. The interfaces will be designed, but the messages being sent between the components will mostly be hardcoded.
This first version will be used to do some first measurements on the real-time characteristics of the architecture. As soon as the coding has finished, a link to the package will be posted here.
After doing the first measurements, the results will be posted here as well.
If you are interested in specific measurements, please let me know. I might include them in my research.
This first version will contain an implementation of all the components in the current architectural design. However, these components will not contain much functionality yet. The interfaces will be designed, but the messages being sent between the components will mostly be hardcoded.
This first version will be used to do some first measurements on the real-time characteristics of the architecture. As soon as the coding has finished, a link to the package will be posted here.
After doing the first measurements, the results will be posted here as well.
If you are interested in specific measurements, please let me know. I might include them in my research.
Monday, May 29, 2006
Presentation
This morning I held a short presentation to share my vision on the project. The handouts for this presentation with the title "SQLbusRT: A first glance" are available at our SourceForge project website.
You can download these handouts directly by clicking this link: SQLbusRT: A first glance
You can download these handouts directly by clicking this link: SQLbusRT: A first glance
Tuesday, May 23, 2006
Support for multiple DB instances
As I mentioned in my previous post, I would change the architecture to support multiple DB instances. In fact, the change was fairly simple, as you can see in the following drawing:
 As you can see, I added a copy of the complete set of components which interact with the database. In the drawing two databases are connected to the bus, but copying the components can be repeated multiple times to allow more db instances to connect to the bus.
As you can see, I added a copy of the complete set of components which interact with the database. In the drawing two databases are connected to the bus, but copying the components can be repeated multiple times to allow more db instances to connect to the bus.
So what are the changes in the scenario?
In the previous design, only one db subscriber requested the sensor data to put it in the database. Again, only one one db publisher was present to publish the query results onto the bus.
In this new design, multiple instances of the db subscriber are reading the sensor data from the bus. They are responsible to pass the information on to their own database that is connected to them. Every database instance has its own publisher to make the data available on the bus again. This means that in normal operation, duplicate data is sent to the bus. However, each db publisher has a different strength on the ORTE bus. Therefore, clients will only receive the data once.
In case a database fails to produce data (for instance, the db connection is broken, or the db is too busy and therefore is not able to produce the data in time) the data from the publisher with the second highest strength is read by the clients.
The great benefit of this design is that no reconnect to a database duplicate is necessary when the master database fails. The second (and third, fourth...) database instance is already up and running and even publishing its data.
 As you can see, I added a copy of the complete set of components which interact with the database. In the drawing two databases are connected to the bus, but copying the components can be repeated multiple times to allow more db instances to connect to the bus.
As you can see, I added a copy of the complete set of components which interact with the database. In the drawing two databases are connected to the bus, but copying the components can be repeated multiple times to allow more db instances to connect to the bus.So what are the changes in the scenario?
In the previous design, only one db subscriber requested the sensor data to put it in the database. Again, only one one db publisher was present to publish the query results onto the bus.
In this new design, multiple instances of the db subscriber are reading the sensor data from the bus. They are responsible to pass the information on to their own database that is connected to them. Every database instance has its own publisher to make the data available on the bus again. This means that in normal operation, duplicate data is sent to the bus. However, each db publisher has a different strength on the ORTE bus. Therefore, clients will only receive the data once.
In case a database fails to produce data (for instance, the db connection is broken, or the db is too busy and therefore is not able to produce the data in time) the data from the publisher with the second highest strength is read by the clients.
The great benefit of this design is that no reconnect to a database duplicate is necessary when the master database fails. The second (and third, fourth...) database instance is already up and running and even publishing its data.
Conceptual architecture
In the past week a bit of collaboration with colleagues resulted in the following conceptual architecture:
 You can look at the project website at sourceforge for an explanation of the different components in this diagram.
You can look at the project website at sourceforge for an explanation of the different components in this diagram.
Soon (perhaps today) I'll post a new conceptual architecture, which lets multiple databases connect to the bus.
Feel free to comment on this architecture!
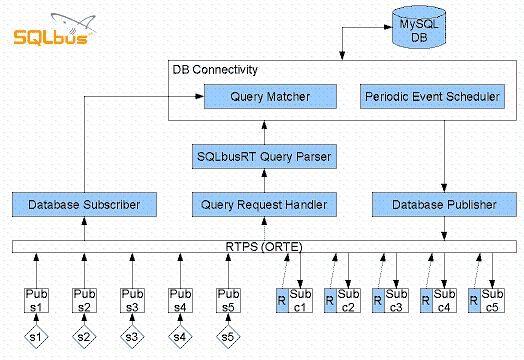 You can look at the project website at sourceforge for an explanation of the different components in this diagram.
You can look at the project website at sourceforge for an explanation of the different components in this diagram.Soon (perhaps today) I'll post a new conceptual architecture, which lets multiple databases connect to the bus.
Feel free to comment on this architecture!
Monday, May 22, 2006
Welcome!
Welcome to my SQLbusRT blog!
My name is Bram Smulders. I recently started my final project for Imtech ICT Technical Systems in Amersfoort, the Netherlands, to finish my Masters degree at the University of Twente.
This blog will be used to keep all interested parties informed on the progress of this project.
So what is SQLbusRT?
SQLbusRT is a bus architecture with database connectivity which lets multiple publishers and subscribers exchange data meeting real time constraints. The benefit of having the database connectivity is that not only new data can be read by subscribers, also history data can be retrieved from the database, still meeting the real time constraints.
Currently the project is in a conceptual phase.
Information on this project
Besides this blog, there's also a website at SourceForge to keep you up to date on the project. You can find it at: http://sqlbusrt.sourceforge.net
The sourceforge website is the main website for this project. You'll find all the information available on this project right there. This blog however is to give you quick updates and to share thoughts with all interested parties. You can (read: you're heartily invited to) post your comments, share your thoughts and give all kinds of ideas related to the project.
Subscribe to:
Posts (Atom)